

The AndPlus Innovation Lab is where our passion projects take place. Here, we explore promising technologies, cultivate new skills, put novel theories to the test and more — all on our time (not yours).


Nearly every project involving relational data storage also involves producing reports on that data for end users. These reports tend to aggregate data from multiple sources, such as joining several tables and reducing them via averages, running totals, time windows or similar. Although modern databases are very efficient, re-running these reports on demand can become expensive. Adding caching to reports results in stale data or the inability to see updates until "close of day." Multi-tenant systems can shard data to different stores, but this still makes cross-tenant reporting for operators difficult.
Kafka provides an intriguing new twist on these and similar problems. Rather than deriving reports after-the-fact from raw data, the raw data is transformed into a pipeline and operated on as it comes in, with the resulting output stored so that applications can quickly look up the final results without recalculating values every time. The output from these stream topologies can still be stored in traditional RDBMSes as well, allowing for a hybrid approach.

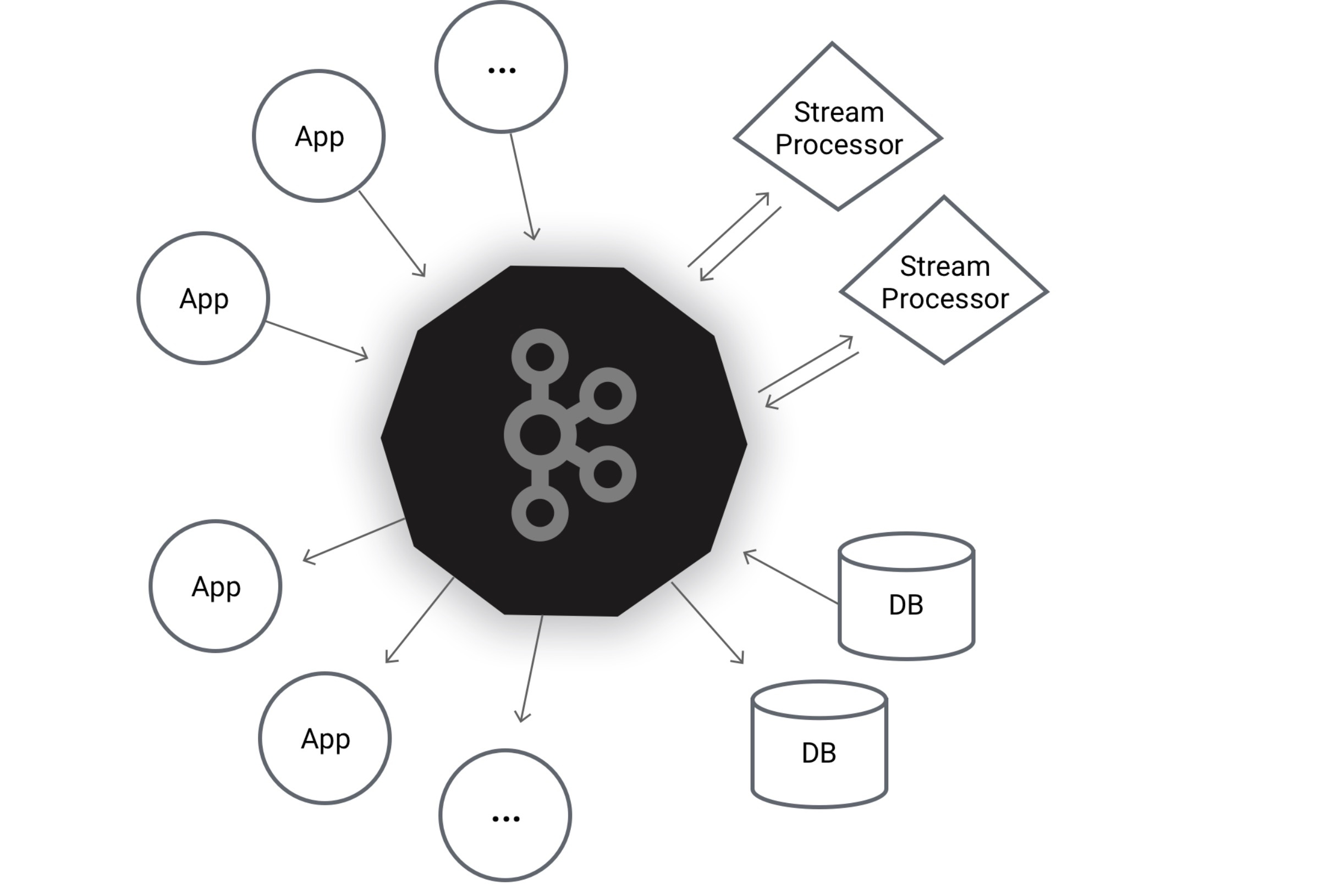
Apache Kafka provides a log-structured stream data structure, called a "topic," which it stores durably across the different nodes in the cluster. These topics can be partitioned and replicated, aiding in multi-tenant style scenarios, as well as providing recovery in the face of failure. We built an application that ingests data from a REST API representing basic financial ledger information and produces several derived reports from the raw events. For example, ledger account events are persisted in one topic, while ledger entries (credits and debits) are persisted in another. The original entries are durably stored by Kafka, and we can then stream these entries, join them with their referenced accounts, and produce updated balances nearly instantly when new entries are recorded.
Kafka provides state stores that allow our application to provide the latest balances for accounts on-demand in response to a normal GET request. Additionally, we built a WebSocket integration that will push batches of updates to subscribed clients, such as a demo web application, so that balance changes can be observed without requiring user interaction or page refreshes. The same model could be used to integrate with mobile push notification systems to power Android or iOS applications as well.
In addition to simple map/filter/reduce operations, Kafka Streams also has sophisticated time-windowing operators. Our demo application also produces an "aged receivable report" showing 30-day buckets of the Accounts Receivable balance based on the original general ledger entries. Rather than recalculating these buckets on demand when a report is requested, Kafka tracks the time windows for us in 1-day intervals, recording the ledger entries into the appropriate bucket. Then, when our application asks the state store for the latest values, we pick the disjoint windows our user requests. Additionally, Kafka supports automatic retention periods so that we do not have to manually remove old windows (past a 120-day lookback period, for example).
There are tradeoffs with Kafka. Initially, we experimented with an application that could perform real-time analysis of invoice payables versus contract agreements. However, allowing a change on either side (the payable or the agreement) and updating the derived records is not yet well supported by Kafka. In this case, a traditional OLAP store may work better. Additionally, Kafka Streams are geared towards pre-defined reports. State stores are simple key-value stores and do not support advanced filtering beyond simple key range queries. Thus, ad-hoc or exploratory reporting is still best supported by traditional database systems.

AndPlus understands the communication between building level devices and mobile devices and this experience allowed them to concentrate more on the UI functions of the project. They have built a custom BACnet MS/TP communication stack for our products and are looking at branching to other communication protocols to meet our market needs. AndPlus continues to drive our product management to excellence, often suggesting more meaningful approaches to complete a task, and offering feedback on UI and Human Interface based on their knowledge from past projects.










