

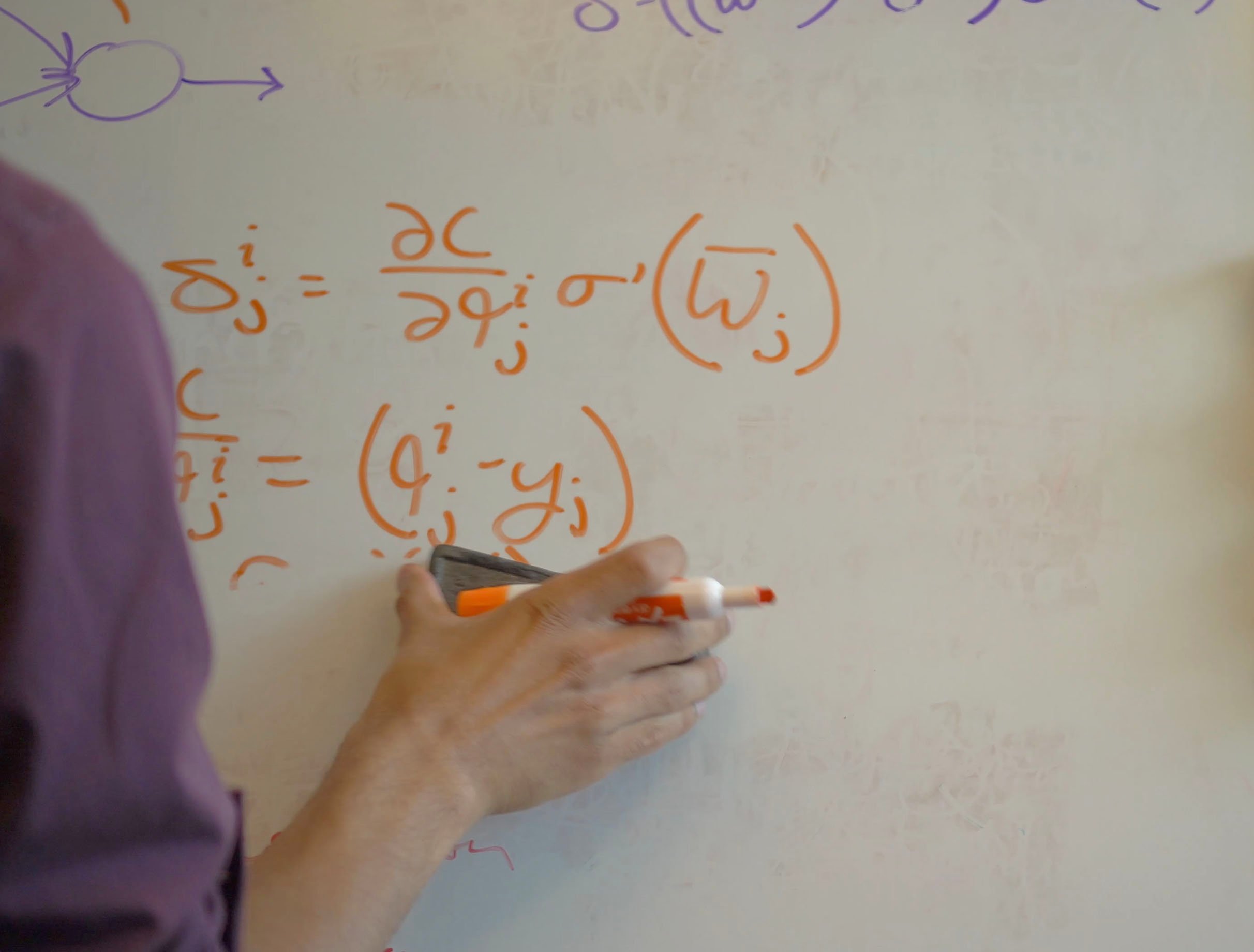
The paper we published is titled 'Tensor based Backpropagation in Neural Networks with Non-Sequential Input'. While it's a bit of a mouthful, the concept can be broken down pretty simply. Artificial neural networks simulate the way the human brain works but with vastly superior speed and accuracy. They never forget, never fatigue and seldom make mistakes. Over the past few years research has led to the advent of more advanced neural network models that allow computers to perform at or above human level on tasks such as visual recognition and on-the-fly language translation. These neural networks are a great resource because they can even excel at a number of tasks that are traditionally viewed as human-exclusive. These tasks span various industries such as medicine, finance and law while even executing more subjective tasks such as art and music.
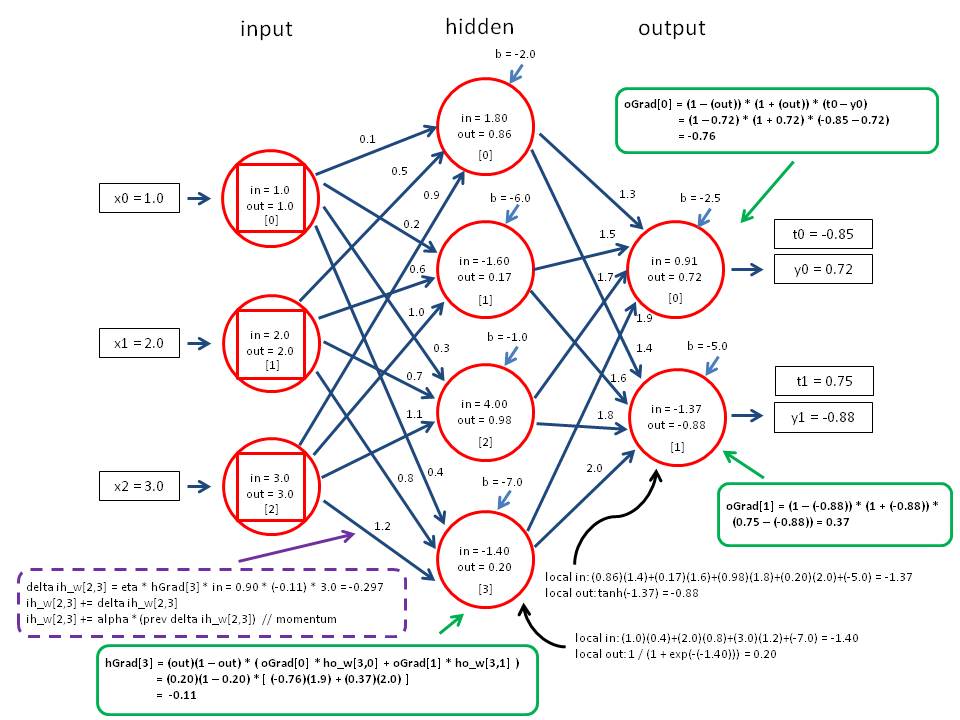
Tensor based batch training is the idea of feeding many data points into the computer at the same time so that it can learn multiple things at once. Unlike humans, Artificial Intelligence can learn from multiple pieces of information at a time. Usually when training is implemented one or more of the steps in the process creates an inefficiency. Our research & development team outlined a mathematical process to avoid such bottlenecks, allowing artificial neural networks learn many things at once.
Neural networks require two primary resources to begin self-learning: Time and Data. Just like humans, an engineer can teach them by first giving a number of examples and eventually they'll catch on. However with complex problems they often require millions of data points (or more!) to begin training effectively. Learning from each example one at a time is slow, often taking months to achieve even with modern computing power.
Our paper outlines a technique of feeding in multiple examples simultaneously to help neural networks learn more quickly. Analogous to the difference between a person learning physics by reading all of the books in the library in order versus reading all of them at once. Using the same technique the learning process can be distributed over multiple machines and the learning can be shared between them all. We’ve demonstrated that this technique can improve learning rates by an order of ten or more, turning a week of learning into only half a day.

Innovation is a big part of the culture here at AndPlus. Having the creative and scientific freedom to conduct research and development in upcoming tech like machine learning, artificial intelligence and big data projects allows us to stay ahead of the curve and provide new solutions for clients.









