

Data warehouses exist to give users rapid, complex data analysis. They’re far better at this than traditional databases, and use different architectures and data management techniques. There are several effective cloud-based solutions that can provide businesses with insights derived from their data. Selecting from and, particularly, implementing these solutions can be complex. In this post, we’ll give an explanation of what a data warehouse is, explain what they’re for and how they differ from other forms of data storage, and look over the biggest players in the space before talking about our own experiences managing data migrations between data warehouse platforms.
What is a data warehouse?
A data warehouse is a system used for reporting and data analysis. It’s not the same thing as a database, partly because it uses different architecture (OLAP vs OLTP; see below), and partly because it’s intended for a different purpose. Databases are for storing and retrieving data; data warehouses are for managing it, processing it, and extracting insights from it.
Data warehousing 101
OLTP vs OLAP
OLTP is On-Line Transaction Processing. This is the processing used by databases, and it focuses on tracking how data is added to them, requested from them and managed within them. While a spreadsheet and a database technically are not the same thing, you can use a spreadsheet to visualize how OLTPs work. You add data, remove it, or update it, and there’s a record of when that happened and who did it. With software and more complex implementations, that usually means a record of where the call came from but the principle is the same.
OLAP is On-Line Analytical Processing systems. The name alone points to a significant difference in emphasis: OLAPs are about analyzing data, not storing it. An OLTP stores data the way we’re used to seeing, in columns and rows. For OLAPs, it might be better to visualize a cube rather than a sheet. In fact, OLAP cubes are how ‘blocks’ or units of OLAPs are usually referred to.
They’re multidimensional data arrays, in the sense that you can sort, search, and analyze them in more axes than the X-Y layout of a spreadsheet. They’re not really ‘cubes,’ in the sense that they’re not ‘databases with one extra dimension’ — they can have as many extra dimensions as you need. When we say ‘cubes,’ it’s just shorthand for ‘data arrays.’
These visualizations only go so far, don’t be distracted by the fact that you have functions and graphs in Sheets or Excel: the difference is fundamental, and it’s about how the data is structured, not about how it’s represented.
OLAP operations
OLAP cubes come in three basic types:
- MOLAP, for Multidimensional OnLine Analytical Processing. These sort data and process it directly in a multidimensional database, so you’re working with the data itself rather than with shortcuts to it. Performance is excellent and flexible, but only certain types of data can be handled.
- ROLAP, for Relational On-Line Analytical Processing. These cubes perform data analysis in a relational rather than a multidimensional database, meaning something like SQL can be used to construct the initial database and processing takes place on top of this database. ROLAP can handle greater quantities of data, but is less efficient of disk space and processing capacity.
- HOLAP, for Hybrid On-Line Analytical Processing. HOLAPs use a hybrid processing model, representing a relational database as a multidimensional one but with the capacity to ‘drill through’ the cube to underlying relational data where necessary. They’re a trade-off in performance between the two models, faster than ROLAP, slower than MOLAP.
Major data warehousing platforms
Amazon and Google both offer data warehousing, with RedShift and BigQuery respectively. Both can deliver analytics rapidly and at scale. Each is best fitted to different use cases, depending on your business needs.
Amazon Redshift
Redshift delivers rapid performance and lets you analyze structured and semi-structured data extremely fast without investment in infrastructure. Redshift can handle data sets of up to a petabyte or more, and that makes it the most common choice for setups that require very large numbers of queries on demand.
However, Redshift also requires very little in the way of initial capital outlay, and can be used on just a few gigabytes of data. Able to grow fast, powered by innovative architectural elements: columnar data storage and massively parallel processing design (MPP), Redshift is a solid choice for smaller businesses too.
Google BigQuery
BigQuery is a serverless data analytics platform that supports standard SQL language. It provides external access to Google’s Dremel technology, which is a scalable, interactive query system for analyzing data.
BigQuery is better for big queries, though. RedShift supports 1,600 columns of data in a single table, while BigQuery supports 10,000 columns, meaning it’s a better choice for very large tranches of data. In addition, RedShift requires periodic management tasks such as vacuuming tables, while BigQuery has automatic management.
RedShift is priced either by Dense Compute, or Dense Storage. The cheapest node available, 150GB with a dc2.large node, costs $0.25 per hour. Dense Storage runs $0.425 per terabyte per hour, which covers both storage and processing. It’s also possible to get RedShift So for $306 per terabyte per month, and upfront payment can net you major discounts on these already reasonable prices.
BigQuery’s pricing is much less transparent; at first glance, it appears to be cheaper, but detailed examination reveals that it really depends on what you use it for. Storage is $20 per terabyte per month, much cheaper than RedShift. But BigQuery charges separately for storage and querying, and queries cost $5 per terabyte. While storage is much cheaper, query costs can quickly add up.
In fact, BigQuery is ideal for businesses that have large data tranches and need to run very fast, maybe-complex queries a few times a day. This business would pay more on RedShift’s per-hour structure, while a company that has a flatter workload might find RedShift works out cheaper.
BigQuery and RedShift aren’t the only competitors in the data warehousing space:
Snowflake
Snowflake is a data warehouse built on top of Amazon Web Services or Microsoft Azure cloud infrastructure. Not only is there no hardware to buy, set up and maintain, there’s no software to purchase either. Snowflake is characterized by its data sharing abilities and its unique architecture, which allows storage and computation to scale independently. This means businesses can pay for them separately too. Snowflake’s sharing functionality makes it easy for organizations to share data securely and in real-time.
Microsoft Azure SQL Warehouse and Synapse
Azure SQL data warehouse is a cloud-based, Platform-as-a-Service tool designed as a large-scale, distributed relational database using Massively Parallel Processing (MPP). Azure is ideal for large-scale analytical workloads, and storage and computing can be decoupled, allowing independent billing and scalability. Azure can also be scaled up or down or even paused, letting users dynamically reserve and pay for the computing resources they need as their workload requirements change.
Synapse is an analytics system that offers similar benefits to Azure SQL Warehouse, including scalability, but also includes non-relational data capabilities, more integrations with other Microsoft technologies, and business intelligence and machine learning integrations as well as greater data ingestion, transformation, management and processing efficiency, especially at large volumes.
Oracle Autonomous Warehouse
Oracle Autonomous Data Warehouse automates provisioning, configuring, tuning, scaling and backup of data. Users get tools for self-serve data loading, data transformations, business modeling, automatic insights and built-in converged database capabilities that enable simpler queries across multiple data types and machine learning analysis. Oracle Autonomous warehouse can be self-hosted or hosted on the Oracle public cloud.
Transitioning to a data warehouse

Transitioning from a database to a data warehouse, or from one data warehouse to another, can be a fairly straightforward process. Data architectures can be cloned and moved across intact in most cases, especially when the migration is from one AWS-supported tool to another. In such cases it’s possible — and recommended — to spin up the new implementation and run it alongside the old one to check before switching the old one off.
An even better way to do this is to use a data warehouse microservice to manage the two warehouse services as data is transferred over gradually, without risk of downtime or data loss.
Case study: Cloud Infrastructure Migration for Onset
When AndPlus migrated Onset’s data from its existing RedShift warehouse to a new Snowflake implementation, we made the selection because RedShift doesn’t allow users to separate computation and storage fees. Snowflake does, so we could design resource usage around the uses Onset required.
As with many businesses, Onset had very specific requirements that were both mission-critical and non-negotiable. A data logging device company, Onset developed a data logging system, InTemp, widely used to read and record vaccine temperature data in transport and at rest. This data must be accurate and accessible, and must be available for reference for up to 3 years, in compliance with CDC regulations.
With these requirements in mind we designed a transition process reliant on microservices.
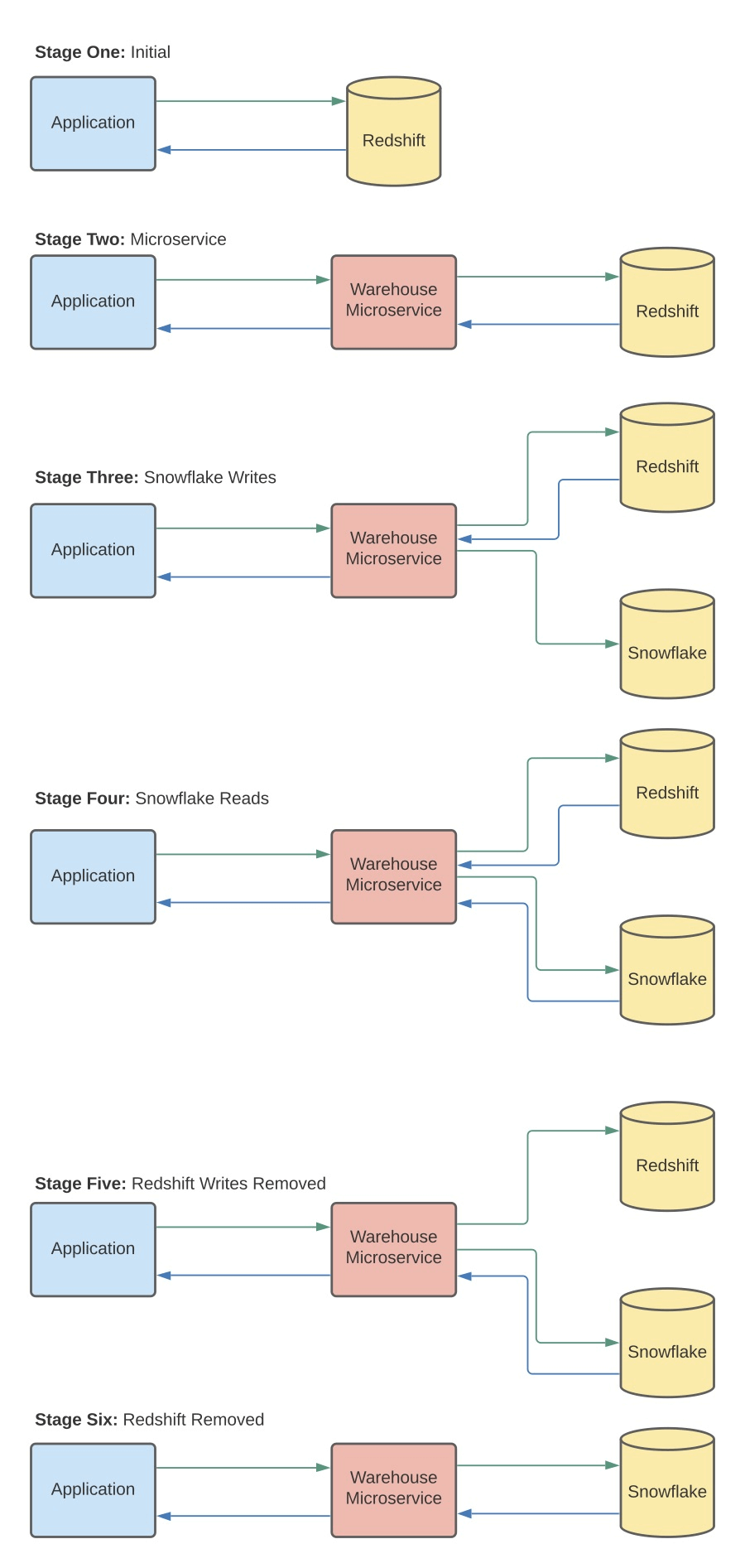
The six-stage process we use to safely and securely transition to a new data warehouse solution
The first step was to plug the extant RedShift warehouse into the warehouse microservice, and the microservice into the application layer. From there, we added Snowflake, spun it up and began transferring data to Snowflake. Gradually, in packets, we moved all Onset’s data across, always making sure it was duplicated and safe. Vaccine delivery depends on accurate, uninterrupted temperature data, so acceptable downtime in this scenario was zero.
When we had OnSet’s data transferred, we operated their RedShift and Snowflake implementations side by side and performed a 1:1 data check on all the transferred data to ensure that the transition had gone without a hitch, before decoupling first RedShift and then the warehousing microservice. Now, OnSet’s application layer runs on top of Snowflake, costing the company less and fitting their needs better. This seamless process, designed to ensure uptime and preserve data integrity, is our standard approach to data warehouse transitions.
Takeaways
- A data warehouse isn’t the same thing as a database. Databases are for storage; data warehouses are for analysis and management.
- There are several industry-leading data warehouse solutions, each with core competencies in common but using different structures and pricing that makes them suitable for different use cases.
- Transition to a new data warehouse solution needs to be handled carefully. It should be done gradually, with data duplicated rather than exported and then checked before the original implementation is discontinued.
Image Credits: People at whiteboard, Featured Image













